Bidirectional Data Replication - Failure Modes and How to Survive Them
I’ve had the opportunity to design and lead several digital transformation engagements where we moved systems from single-site or dual-site active-failover setups to active-active architectures. In some cases, we stopped at the application tier; in others, we pushed all the way to active-active at the data/DB layer.
Active-active means both sites serve live traffic simultaneously. I’ve designed both patterns - active-active for BT Openreach and du, active-passive database replication for du’s Oracle RAC tier.There are solid reasons to choose either active-active or active-passive at the data tier - but I’ll leave that debate for another day.
This post focuses on my own experience - very much hard-earned - running active-active at the database level. Following is a distilled view of those real-world scenarios and the solutions that actually held up in production.
What is Realtime Bidirectional Data Replication
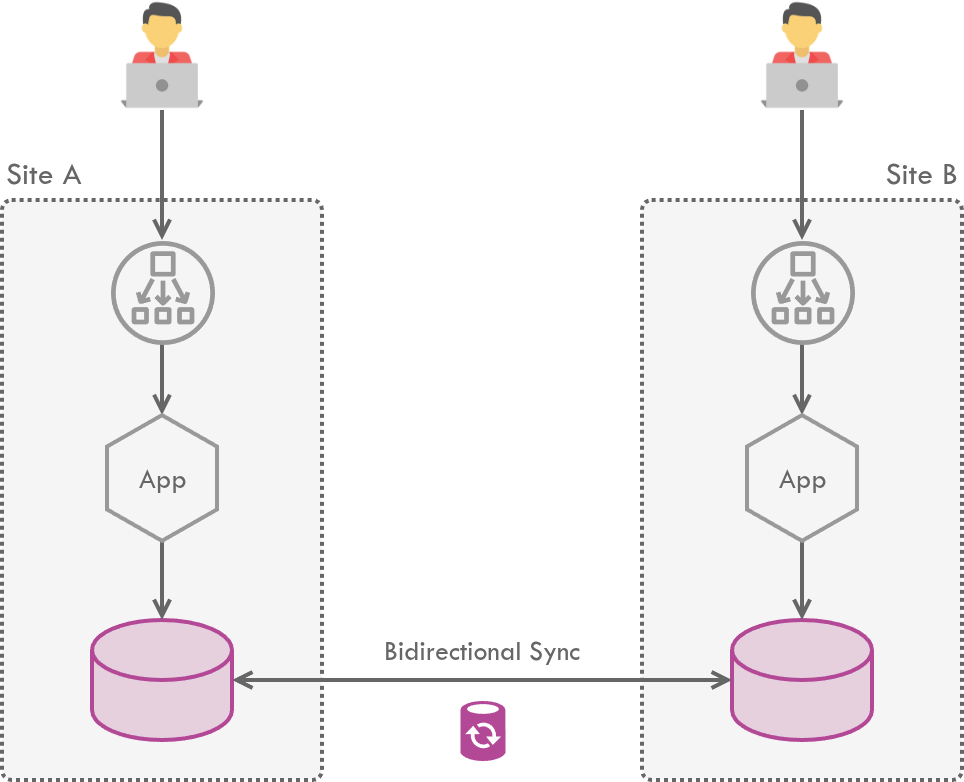
Enterprise systems are often deployed across multiple data centers to achieve high availability and geographic resilience. Keeping data consistent across these sites requires reliable replication between them. And when both sites actively serve live traffic - an active-active setup - the databases need to support bidirectional replication.
The foundation of this architecture is Change Data Capture (CDC) - capturing row-level events in a database and replicating them elsewhere. While many event-driven systems often use open-source CDC platforms like Debezium (which streams database changes through Kafka), enterprise databases running in active-active setups have traditionally relied on log-based CDC systems like Oracle GoldenGate. The conflict patterns we’ll discuss here apply no matter which CDC platform is in use. Oracle GoldenGate, in particular, enables real-time bidirectional data replication, filtering, and transformation across heterogeneous databases.
Sync Lag
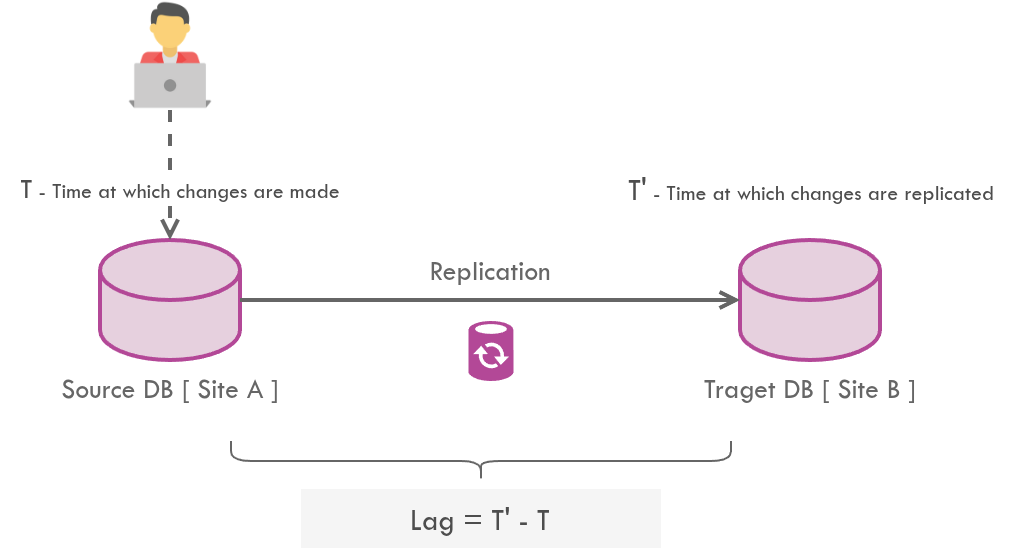
Technologies providing real-time data replication between databases (such as Oracle GoldenGate), despite being advertised as real-time, have a latency.
The lag is the interval of time between making changes to the source database and having those changes replicated on the destination database.
In case of bidirectional sync, there will be a couple of sync jobs (from Site A → B and Site B → A) - each will have different lags per transaction.
The lag, and the fact that it varies upon each transition, has a negative impact on database consistency.
Potential Issues with Bidirectional Sync
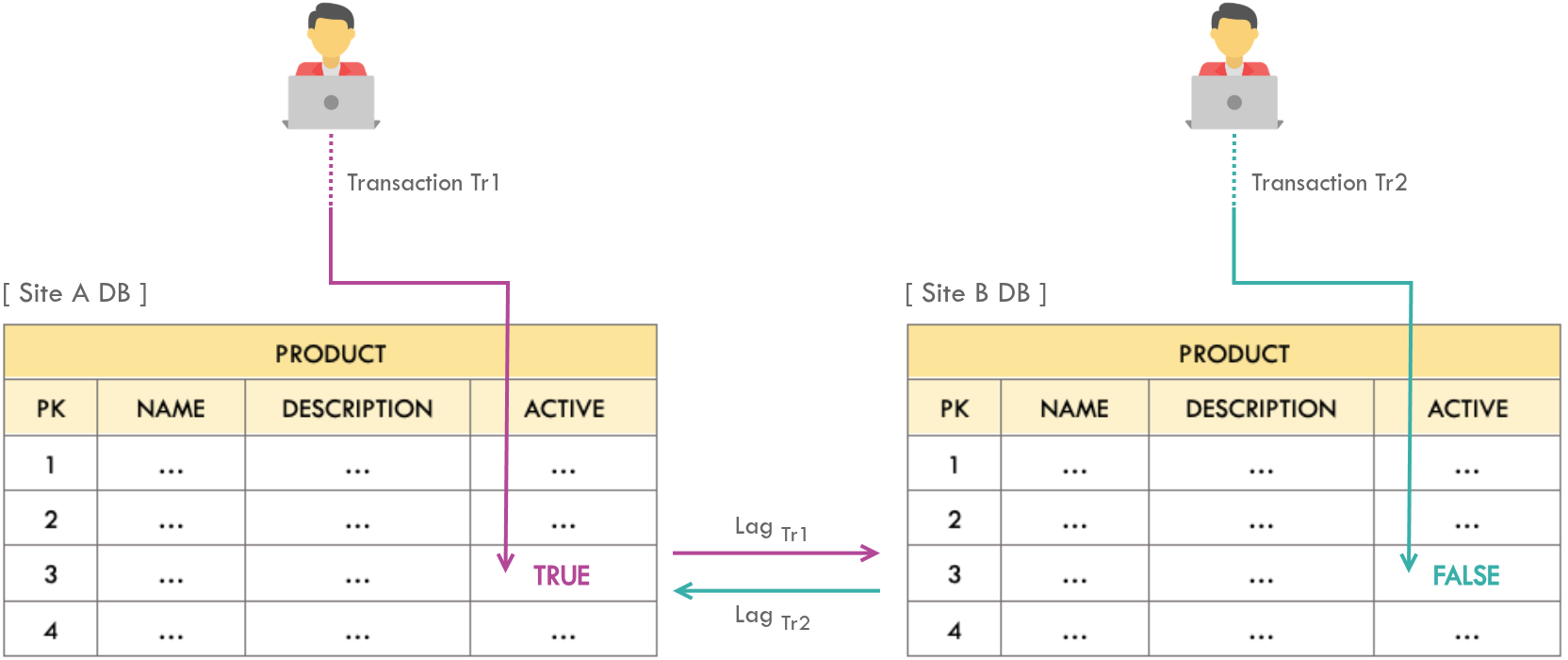
1. Update Conflicts
Issue
A given row gets updated from both the sites simultaneously. After the sync, the final state of both databases must be the same as the database at the site where the most recent change occurred, irrespective of the lags. However, the most recent values may be overridden by the older update due to sync lag.
Solution
This is a last-writer-wins strategy. It guarantees convergence (both sites end up identical) but not necessarily correctness (the “right” value wins). For most telecom subscriber operations, convergence is sufficient.
- Add a timestamp column to tables that represents the last updated date/time.
- Configure the database such that the current timestamp is automatically added to the “last updated” column of the row being updated/inserted.
- This enables the sync job to skip replicating an update on the target DB, if the target DB’s corresponding row’s last updated timestamp is greater than that of the source site.
Implementation
In Oracle 11g+, adding a column with a DEFAULT value is a metadata-only operation - no table lock, no outage. Safe for zero-downtime production cutovers.The timestamp column can be added with a DDL statement as follows. It is recommended to define this column to be NOT NULL. In the event of a migration, this DDL can be applied during the production cutover since the timestamp column has no impacts to existing records.
ALTER TABLE <table_name>
ADD (LAST_UPDATED TIMESTAMP (9) DEFAULT CURRENT_TIMESTAMP NOT NULL ENABLE)
Alternatively a trigger may be introduced to automatically add the timestamp for databases that are incapable of adding the DEFAULT value for UPDATE statements (e.g. Oracle RDBMS does not automatically add the DEFAULT value for UPDATE statements, but INSERT statements). This trigger must be introduced for every concerned table, however there will not be any performance impacts.
CREATE OR REPLACE
TRIGGER <trigger_name>
BEFORE UPDATE ON <table_name>
FOR EACH ROW
BEGIN
:NEW.LAST_UPDATED := SYSTIMESTAMP;
END;
Alternatively the timestamp may be calculated and added from the code level (of the application). However this cannot be recommended due to following reasons:
The infrastructure concern of replication timestamps should not leak into application code - the same way you wouldn’t put load balancer configuration in your service layer.
- Violates the Principle of Least Knowledge. The
LAST_UPDATEDcolumn is to solve an infrastructure concern, not an application/business concern. Therefore having logic to calculate timestamp at code level leaks such concerns to the app tier. - Higher effort - due to the fact that a single table may be updated from multiple app tier services.
- Higher effort - due to the fact that it invokes updating multiple files such as Repository and Entity.
- Higher cognitive load since different app tier services may be using different DB access patterns and strategies (e.g. Hibernate in one app and JDBC in another).
- Human error may prevent the addition of an updated timestamp. Failing to amend an artefact which updates database tables in cases where tables are updated from numerous artefacts, such as scripts that are only available to production support teams, stored procedures maintained by DBAs, or tables accessed via DB Links by B2B components.
Applicability
The LAST_UPDATED column may not be required for all the tables, but transactional tables where there is a possibility to have simultaneous updates from live users.
Transactional tables can be identified by monitoring tables in production (if there is already one) for a considerable period of time. In case of Oracle RDBMS, the DBA_TAB_MODIFICATIONS view shows the tables that are updated (i.e. tables with at least 10% of the rows have changed) since statistics on those tables were last obtained.
Following non-transactional tables may be omitted from introducing the LAST_UPDATED column:
- Scheduler tables (i.e. QUARTZ_XXX) - Scheduler tables may be deployed only on a single site. Even if the schedulers are run in both the sites, the cron may be configured to execute the jobs at different time slots.
- External tables - These tables are usually synced at the file system level.
- Tables that are never updated by applications due to live user traffic, but are updated via scripts by maintenance teams.
2. Insertion Conflicts
Issue
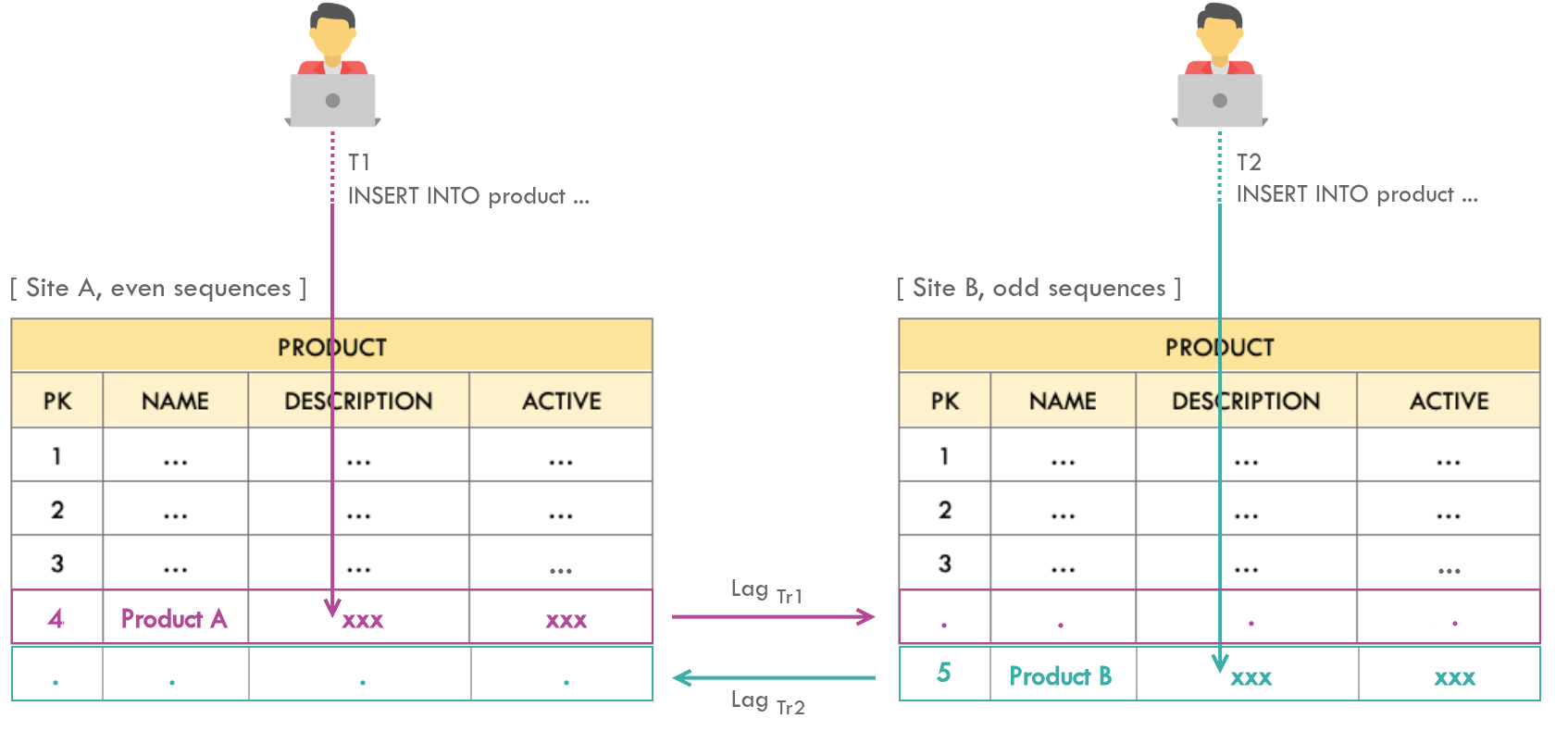
A given table gets inserted from both the sites simultaneously. Consequently, two valid records will have the same primary key in different sites. During the sync, a given primary key with most recent record will override that of the other site (based on LAST_UPDATED), otherwise the replication with least lag will take precedence.
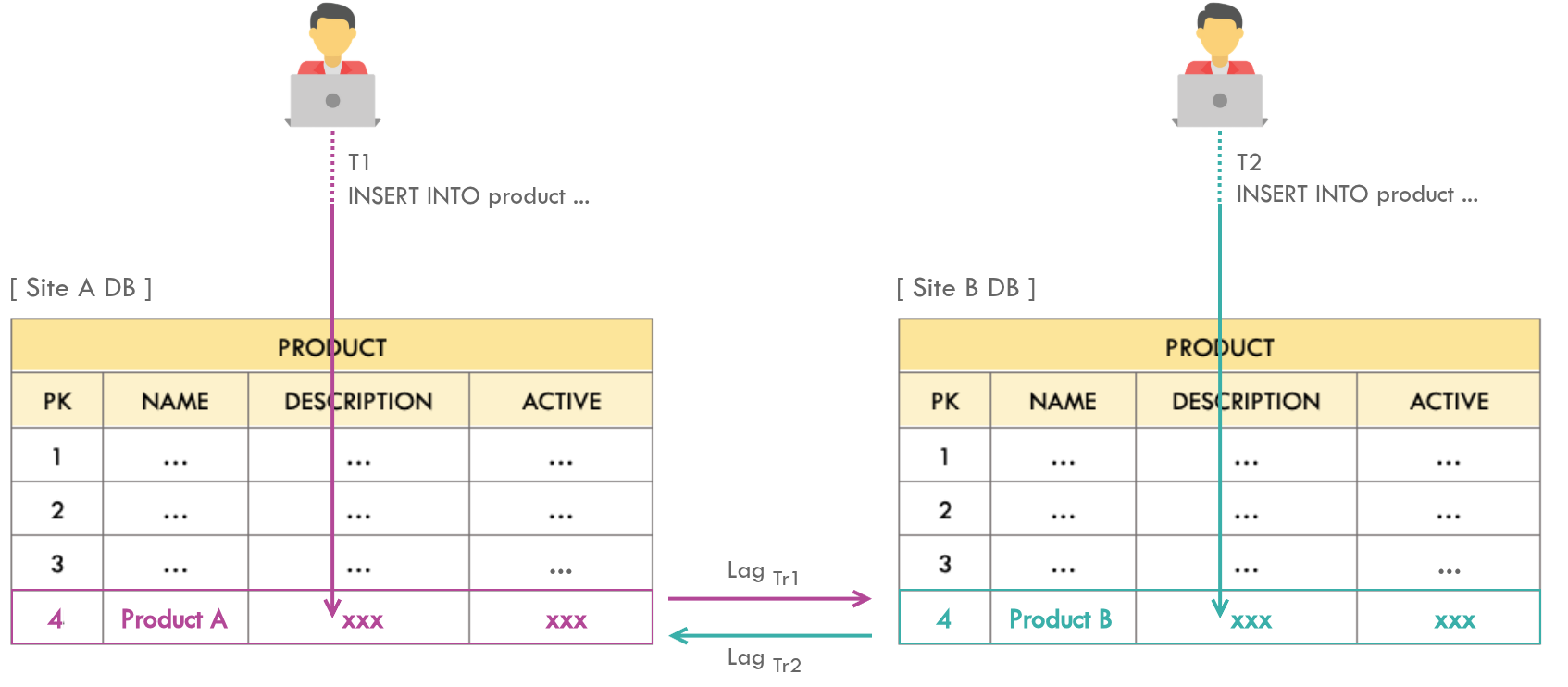
If LAST_UPDATED strategy is in place and $T1 > T2$, then the row identified by primary key 4 will have Product A in both the sites after sync and Product B record will be lost.
If LAST_UPDATED strategy is not in place and $Lag_{Tr1} > Lag_{Tr2}$, then the row identified by primary key 4 will have Product B in both the sites after sync and Product A record will be lost.
Solutions
UUIDs eliminate insertion conflicts entirely but destroy B-Tree index locality, causing page fragmentation and memory bloat at high throughput. For telecom-scale systems serving millions of subscribers, odd/even sequences usually win.
- Option 1: Use UUIDs for primary keys.
- Option 2: Introduce odd/even sequences through which insertions should occur. Sequences of Site A should produce odd values and that of Site B should produce even values, or vice versa.
-- Site A, odd sequence
CREATE SEQUENCE <sequence_name>
MINVALUE 0 MAXVALUE 9999999
INCREMENT BY 1 START WITH 1;
-- Site B, even sequence
CREATE SEQUENCE <sequence_name>
MINVALUE 0 MAXVALUE 9999999
INCREMENT BY 2 START WITH 2;
If a table is inserted by multiple artefacts, such as an app in the app tier, stored procedures, robotics, etc., a trigger can be set up to automatically add the primary key using a named sequence.
-- Trigger to automatically set ID before inserting
CREATE OR REPLACE TRIGGER <trigger_name>
BEFORE INSERT ON <table_name>
FOR EACH ROW
BEGIN
:new.<primary_key_column> := <sequence_name>.nextval;
END;
Applicability
- If a table is only inserted and never changed, it does not need a timestamp column, as insertion conflicts can be totally eliminated by only using odd/even sequences.
- Prevention of insertion conflicts may not be required for all the tables, but transactional tables where there is a possibility to have simultaneous insertions from live users.
- Following transactional tables may be omitted from introducing the odd/even sequences or UUIDs as primary keys:
- Tables with composite primary keys (either mapping tables or entity tables) - If the composite primary key is same across multiple sites, only one of the sites’ records should be valid in the event of an insertion.
- Tables that are in total-participation with their parent tables - i.e. primary key of a table is a foreign key that references the primary key of the parent table. Insertion conflicts will be prevented if the parent table has odd/even sequences or UUIDs as primary keys.
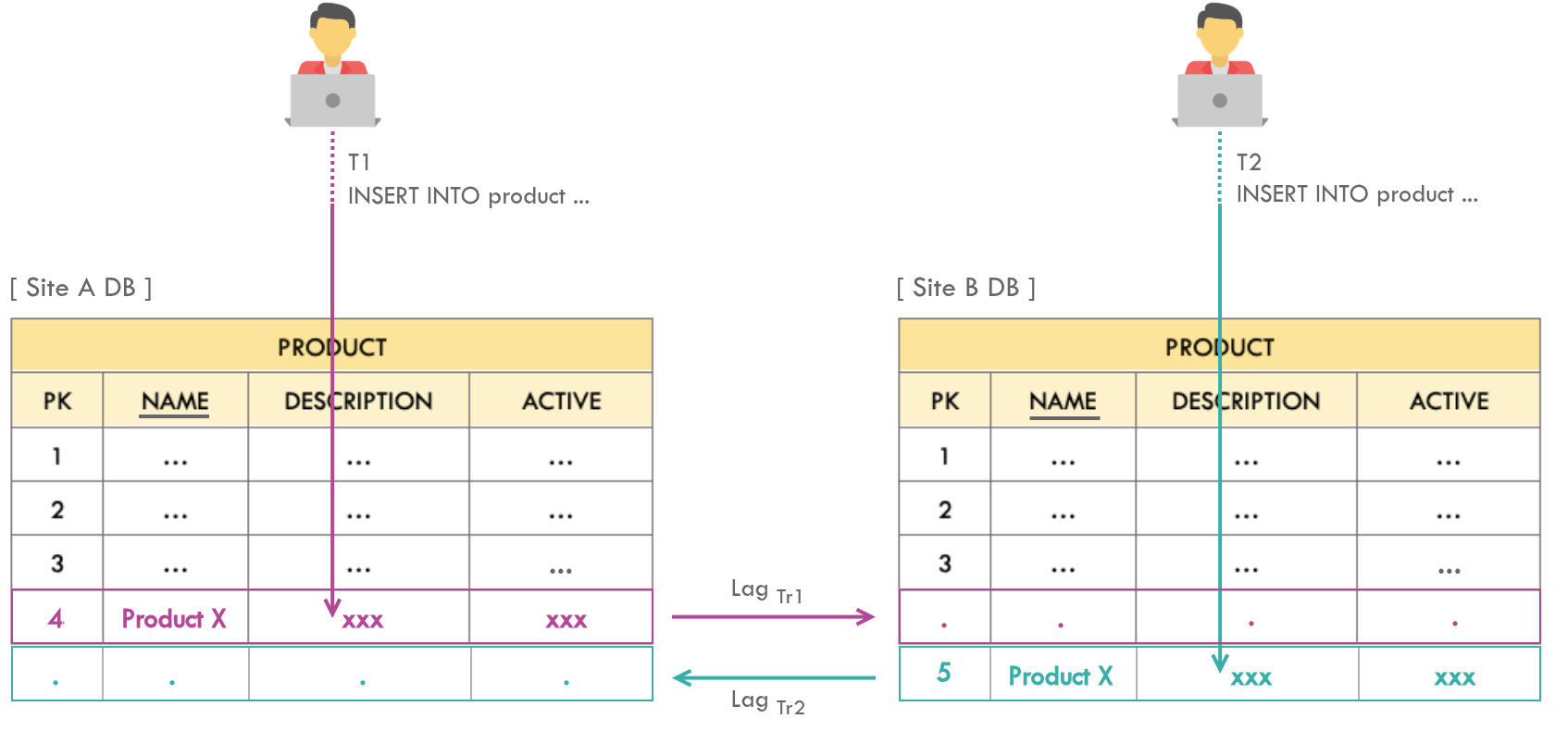
3. Unique Key Constraint Violations
Issue
A given table gets inserted from both the sites simultaneously, with the same value for a non-primary unique key column. During the sync, this will result in a unique key constraint violation.
Solutions
This is an inherent trade-off of AP systems. Full prevention would require cross-site coordination before every write - effectively a distributed lock, which defeats the purpose of active-active.There are no design-time solutions to prevent this from happening. The necessary actions should be taken by the production support teams, such as restarting the aborted sync jobs, once this occurs in production.
Applicability
There is a lower possibility for the following tables to have unique key violations:
- Non-transactional tables with no possibility to have simultaneous insertions from live users.
- Tables that can only be inserted by logged-in users and the system supports sticky sessions.
4. Consequences of Tables Without Primary Keys
Issue
Oracle GoldenGate recommends having primary keys for all the transactional tables because in the absence of a unique/primary identifier, Oracle GoldenGate uses all of the columns of the table in a WHERE clause to filter the row in the target database table for replication. However this will degrade performance of the sync if the table contains numerous columns.
Solution
If a primary key is available, the WHERE clause will only have the primary key and it is performant since the primary key is indexed.
Applicability
Non-transactional tables may not need primary keys (if they don’t already have one), especially if they don’t need to be synced between sites.
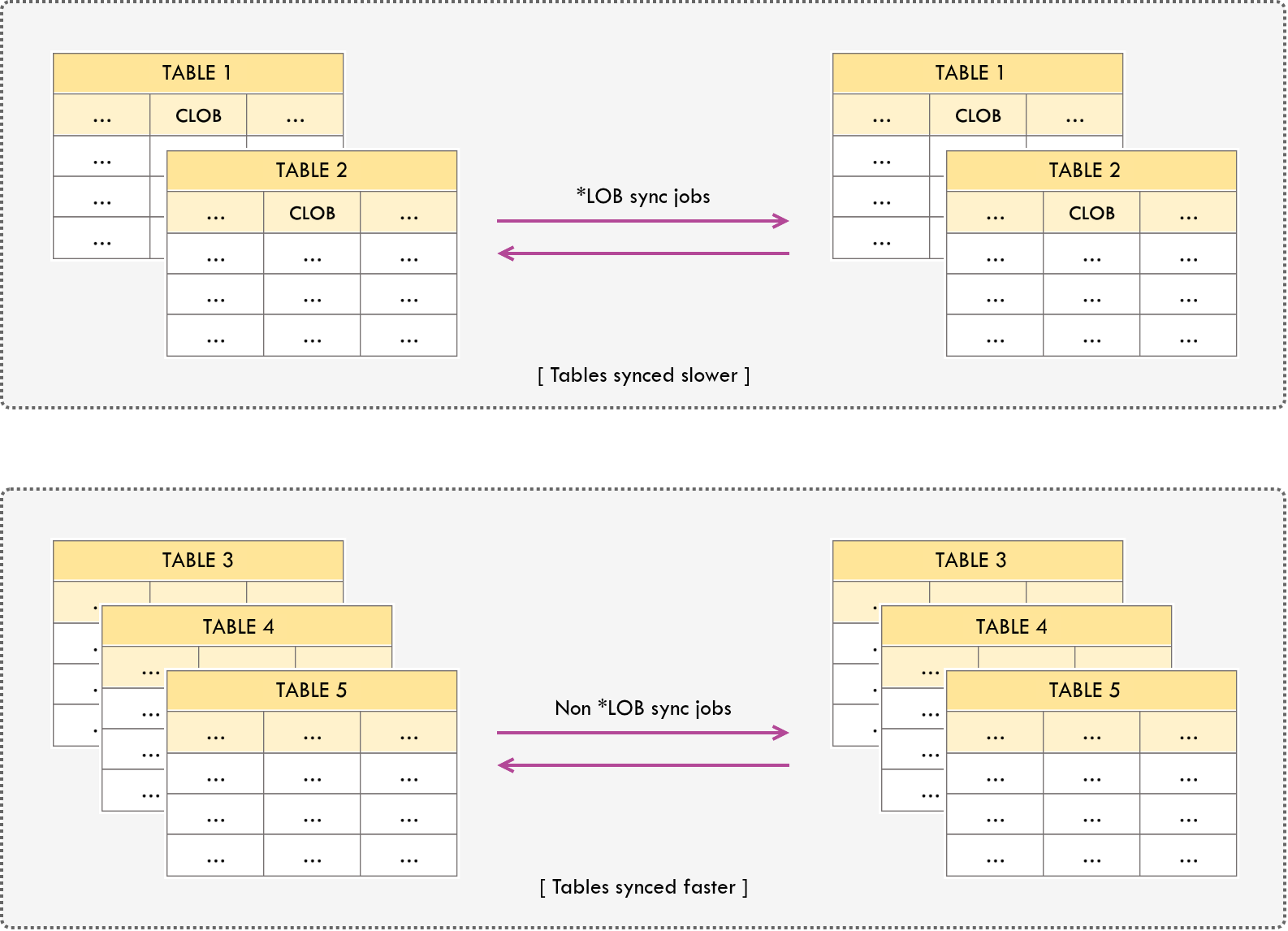
5. Consequences of Tables Having CLOB or BLOB Types
Issue
Replicating update or delete operations of records with CLOB or BLOB types are slow.
Solution
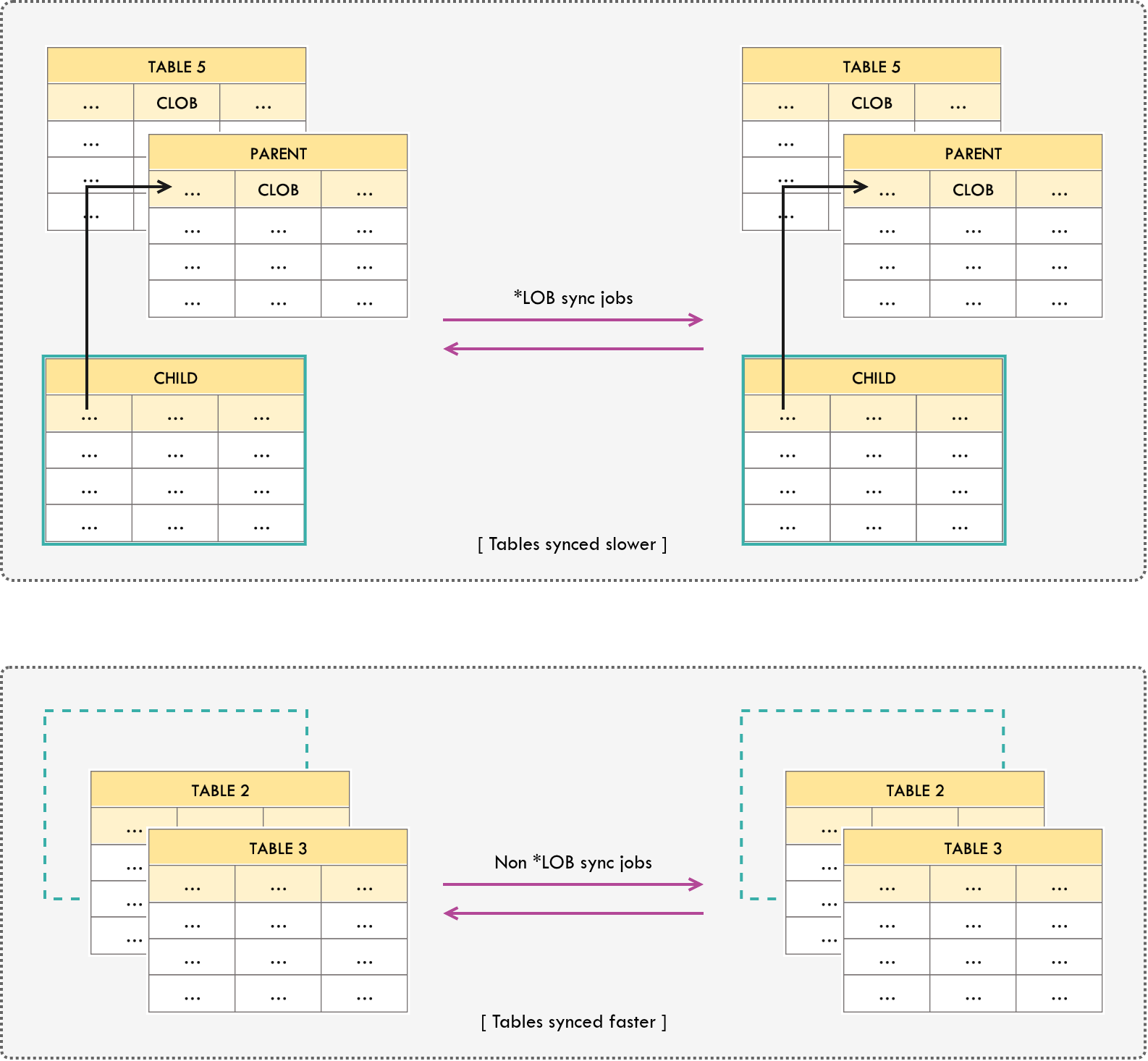
CDC tools read transaction redo logs sequentially. LOB data forces out-of-line fetching that breaks sequential read performance. Isolating LOB tables prevents this from starving your fast-path transactional replication.Isolate tables with CLOB or BLOB types into a separate sync job, in order to prevent slowing down the overall replication process.
A referential integrity violation can occur in the following situation: given that the sync job separation described above is in place, and there is a parent-child relationship between a table with *LOB types (parent) and a table without *LOB types (child). This is due to the fact that the child table records on the faster sync job are replicated prior to the parent table records on the slower sync job.
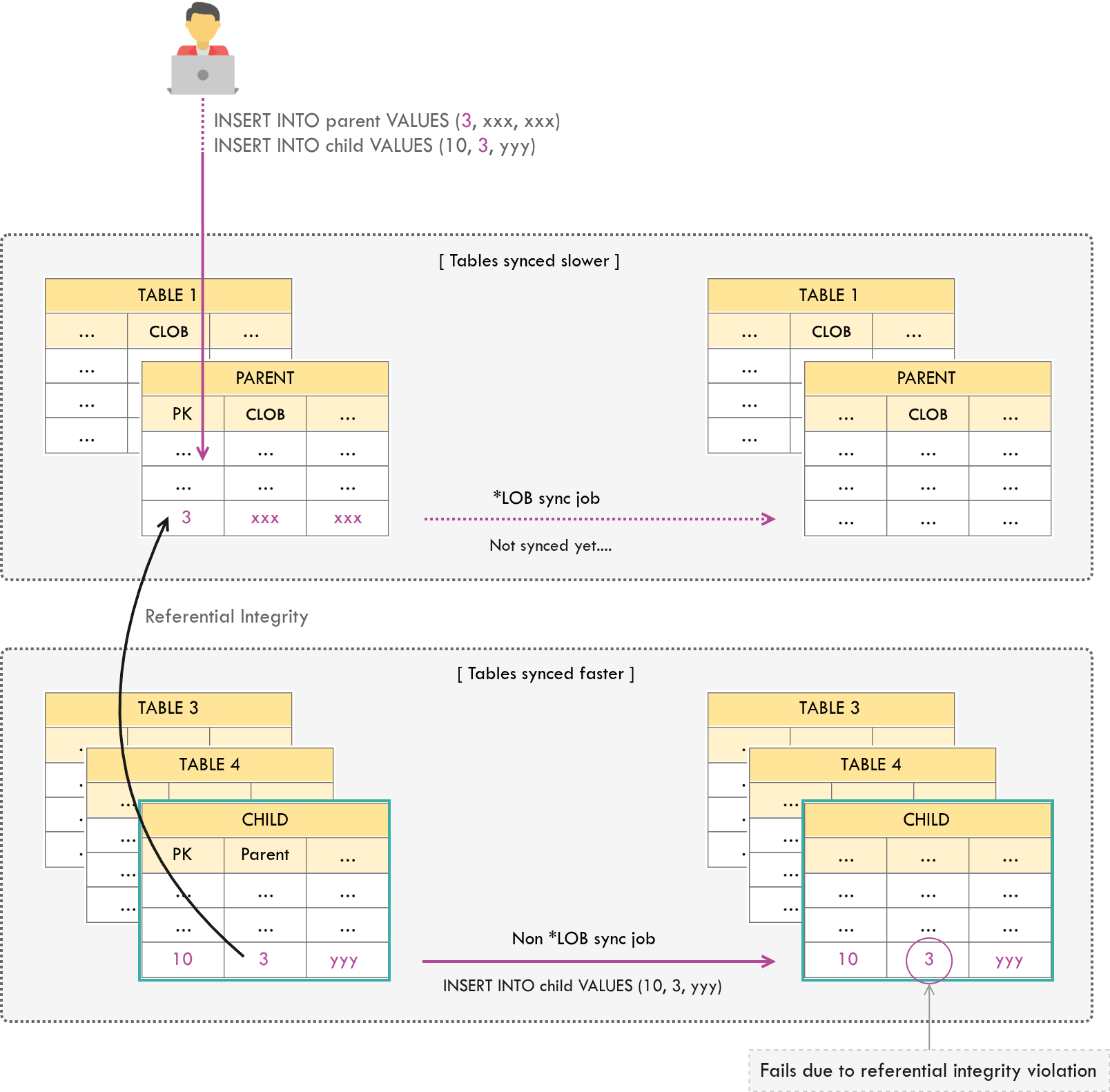
Therefore, direct child tables of parent tables that have *LOB types should also be moved to the isolated sync job.
6. Deletion Conflict
Issue
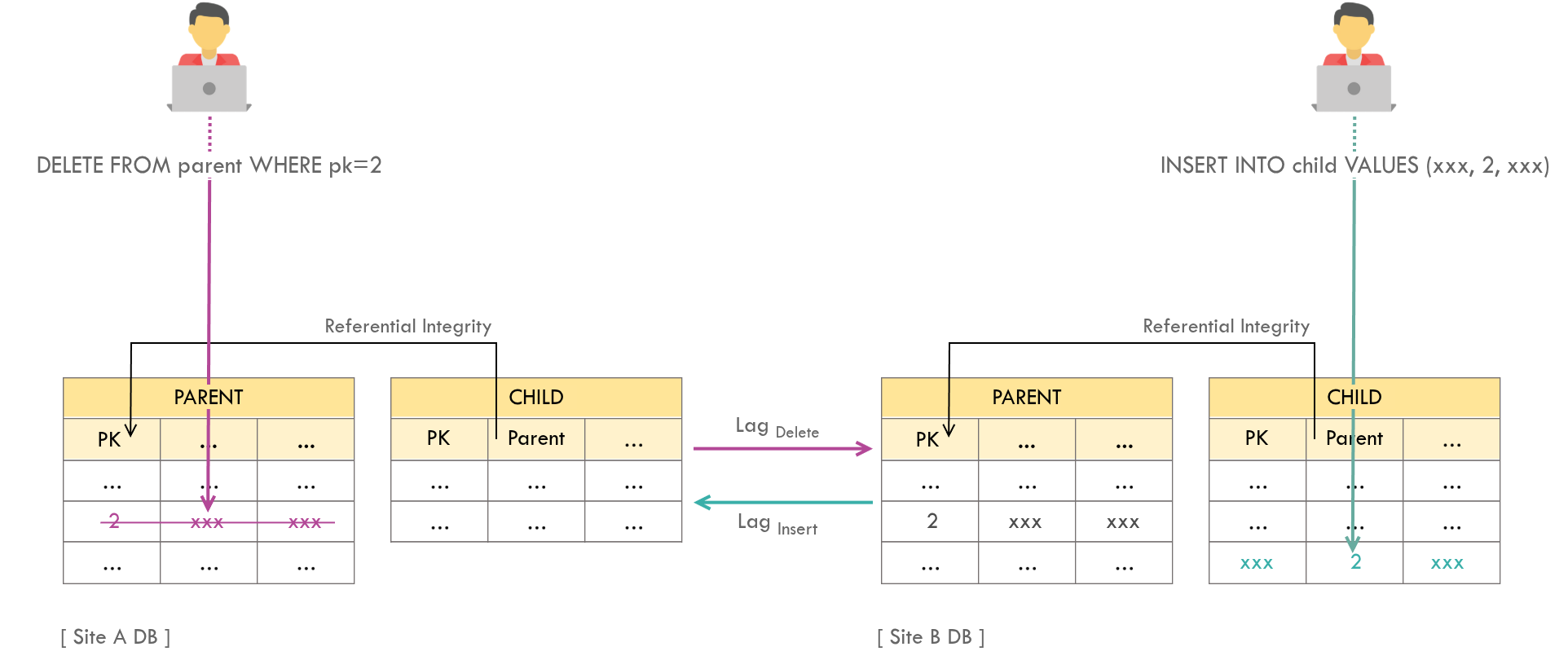
A deletion conflict occurs given that there is a parent-child relationship between 2 tables and the following 2 operations happen simultaneously:
- A row in parent table is deleted on one site.
- A new row - referencing the parent row being deleted - is inserted on the other site.
Deletion conflict occurs if the sync lag of the deletion operation is greater than that of the insertion operation. This will result in a referential integrity violation (“parent key not found” error in case of Oracle RDBMS).
Solutions
Soft deletes (marking rows as deleted rather than physically removing them) eliminate this class of conflict entirely, at the cost of storage and query complexity.There are no design-time solutions to prevent this from happening. The necessary actions should be taken by the production support teams, such as restarting the aborted sync jobs, once this occurs in production.
Applicability
There is a lower possibility for the following table pairs to have deletion violations:
- Non-transactional table pairs with no possibility to have simultaneous insertions and deletions from live users.
- Table pairs that can only be inserted and deleted by logged-in users, and the system supports sticky sessions.
A Note on How Replication Works
A question worth addressing: are INSERTs replicated as INSERTs on the target database? If so, the target site might have some additional INSERTs by the time replication takes place from the other site. Consequently, a given record might have a greater primary key value on the target site.
The answer is no. In logical replication tools like Oracle GoldenGate, the Extract process captures the committed data from the transaction log (redo logs) and propagates the final actual data values, including the data generated with triggers and sequences. If Site A inserts a row and the sequence assigns it ID = 15, GoldenGate sends this exact statement to Site B: INSERT INTO table (ID) VALUES (15). It does not trigger Site B’s sequence generator.
Therefore, the primary key value remains exactly the same across both sites. This is exactly why Option 2 - Odd/Even Sequences - is the correct and necessary architectural pattern to avoid ID = 15 being generated simultaneously on both sites before replication catches up.
While this article focuses on Oracle GoldenGate, the conflict patterns described here apply to any bidirectional replication system - including Debezium, AWS DMS, and PostgreSQL logical replication. I’ve contributed to Debezium’s error handling framework and encountered variations of these same challenges in event-driven CDC architectures. The resolution strategies remain largely the same regardless of the underlying platform.
The architectural patterns discussed in this article are being expanded into a formal taxonomy paper for academic publication.